
CRC Tracker
A data collection web-scraper built in Python.
Spring 2024
About the Project
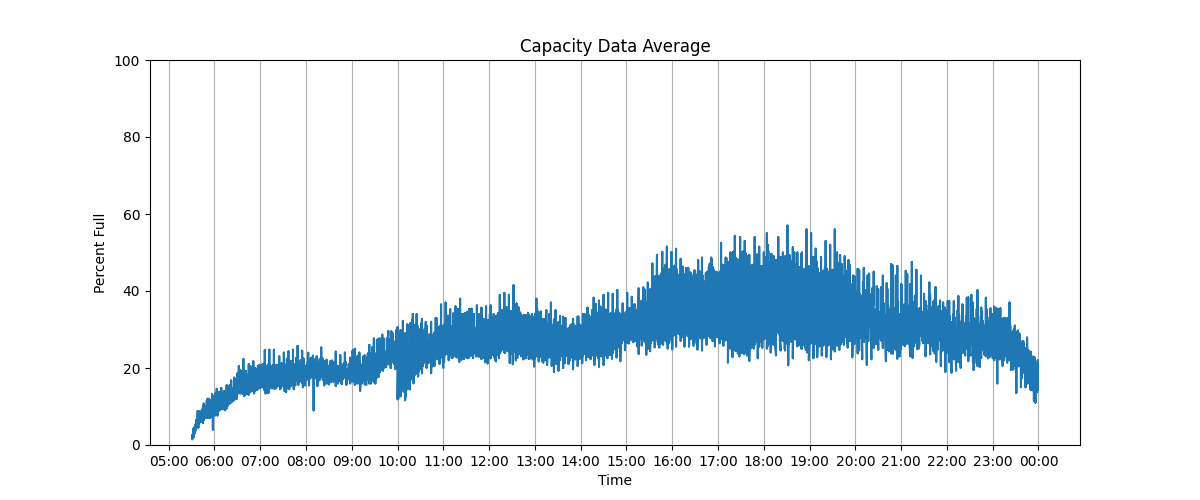
The CRC Tracker project was motivated by the fact that, while current live data for the Georgia Tech gym capacity can be found online, nowhere can one view trends or historical data. With this project, you are able to do things such as isolate specific dates or weekdays, compare weekdays, or view hourly and daily averages. Since data is stored in a (date, percent_full) format, there are an infinite number of analyses that can be performed.
This project collected live data from https://live.waitz.io/4vxie66a29ct via the Selenium Python package and stored the percent full attribute in a local SQLite database. The data was then manipulated via SQL queries and plotted with the Python Matplotlib package, with figures being uploaded to Google Drive nightly via the Paramiko package. The web scraper and database were run continuously on a Raspberry Pi.
GitHub Repository: github.com/holdencasey7/crc-busy-webscraper


Skills
-
Python
-
SQL
-
Raspberry Pi
-
Selenium
-
Matplotlib
-
Paramiko